Kafka 용어 정리 (pub/sub, 토픽, 파티션, 브로커)
Pub/Sub 모델이란?
Pub/Sub 모델(Publish-Subscribe Model)은 분산 시스템에서 메시지 전달을 처리하기 위한 패턴 중 하나입니다. 이 모델에서는 메시지 송신자(publisher)가 메시지를 특정한 주제(topic)로 발행(publish)하면, 해당 주제를 구독(subscribe)하고 있는 여러 수신자(subscriber)들이 메시지를 수신(receive)합니다.
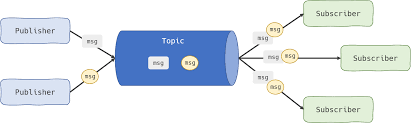
Pub/Sub 모델은 다음과 같은 특징을 가집니다.
- 비동기성(Asynchronous): 메시지 발행과 수신이 동기적으로 이루어지지 않습니다. 메시지 발행 시간과 수신 시간이 다를 수 있으며, 메시지 송신자는 수신자가 메시지를 받았는지 여부를 알 수 없습니다.
- 느슨한 결합(Loose Coupling): 메시지 송신자와 수신자 간의 직접적인 연결이 없습니다. 메시지 송신자는 메시지를 발행하는 주제만 알고 있으면 되며, 수신자는 해당 주제를 구독하면 됩니다. 이로 인해 시스템의 유연성과 확장성이 높아집니다.
- 확장성(Scalability): 메시지 발행자와 수신자 간에 병목 현상이 발생하지 않습니다. 메시지를 발행하는 쪽에서는 다수의 수신자가 있더라도 추가 작업을 할 필요가 없으며, 수신자에서도 다수의 발행자가 있더라도 추가 작업을 할 필요가 없습니다.
Pub/Sub 모델은 메시지 브로커(message broker)를 통해 구현될 수 있습니다. 메시지 브로커는 메시지를 발행하는 쪽과 수신하는 쪽을 연결해 주며, 이를 통해 메시지 발행과 수신을 중재합니다. 대표적인 메시지 브로커로는 Apache Kafka, RabbitMQ, Amazon SNS 등이 있습니다.

Pub/Sub 모델의 대표적인 예시 중 하나는 메시지 브로커를 사용하는 메시지 큐 시스템입니다. 이 시스템에서는 Publisher(발행자)가 메시지 브로커에게 메시지를 발행하면, 해당 메시지를 구독하는 Subscriber(구독자)가 해당 메시지를 구독하여 처리합니다.
예를 들어, 여러 사용자가 있는 온라인 스토어에서는 사용자가 주문을 하면, 해당 주문 정보를 메시지 큐에 발행합니다. 주문 정보를 구독하는 서비스들은 해당 주문 정보를 받아서 각각의 역할에 맞게 처리합니다. 예를 들어, 주문 정보를 받아서 결제 서비스는 해당 주문 정보를 가지고 결제를 진행하고, 배송 서비스는 해당 주문 정보를 가지고 상품을 포장하고 배송을 준비합니다.
이러한 Pub/Sub 모델은 다양한 분산 시스템에서 사용됩니다. 예를 들어, 로그 수집 시스템에서는 로그 메시지를 발행하고, 해당 로그를 분석하는 서비스들이 해당 로그 메시지를 구독하여 분석합니다. 또한, 실시간 데이터 처리 시스템에서는 실시간으로 발생하는 이벤트를 발행하고, 해당 이벤트를 처리하는 서비스들이 해당 이벤트를 구독하여 처리합니다.
이처럼 Pub/Sub 모델은 분산 시스템에서 메시지 기반 아키텍처를 구현할 때 매우 유용하게 사용됩니다. 메시지 큐 시스템을 비롯하여, Kafka, RabbitMQ, AWS SNS/SQS 등 다양한 메시지 브로커와 함께 사용됩니다.
Kafka에서의 토픽(Topic)이란?
Kafka에서의 토픽(Topic)은 메시지를 주고받는 주제를 의미합니다. 토픽은 Kafka 클러스터 내에서 메시지를 발행하고 구독하는 데 사용됩니다. 간단하게 말하면, 토픽은 메시지가 저장되는 주소 역할을 합니다.
Kafka에서 토픽은 여러 개의 파티션(Partition)으로 구성됩니다. 파티션은 각각의 브로커에 분산되어 저장되는 데이터 단위입니다. 각 파티션은 순서가 보장되며, 일련의 메시지를 저장하고 관리합니다. 이렇게 파티션을 사용함으로써, Kafka는 대규모 데이터를 빠르게 처리하고, 확장성을 높일 수 있습니다.

또한, Kafka는 각 토픽마다 여러 개의 구독자(Consumer)를 지원합니다. 구독자는 각 파티션에 대한 offset을 관리하면서, 해당 파티션에서 발생한 메시지를 읽습니다. 이렇게 Kafka는 여러 개의 구독자가 동시에 동일한 토픽에서 메시지를 읽을 수 있도록 지원합니다.
예를 들어, 온라인 스토어에서는 주문 정보를 저장하는 "order"라는 토픽이 있을 수 있습니다. 이 토픽은 다양한 파티션으로 구성되어, 주문 정보를 효율적으로 저장하고 관리합니다. 또한, 결제 서비스, 배송 서비스 등 여러 구독자들은 "order" 토픽의 각 파티션에서 발생한 주문 정보를 읽어서 각각의 역할에 맞게 처리합니다.
이처럼 Kafka에서의 토픽은 대규모 분산 시스템에서 메시지 기반 아키텍처를 구현할 때 매우 유용하게 사용됩니다. Kafka는 대용량 데이터를 처리할 수 있는 높은 처리량과 확장성을 제공하며, 이를 통해 다양한 분산 시스템에서 활용됩니다.
Kafka에서 파티션이란?
Kafka에서 각 토픽은 하나 이상의 파티션으로 구성됩니다. 각 파티션은 토픽 내에서 메시지를 구분하는 단위이며, Kafka는 각 파티션에 메시지를 순서대로 저장합니다. 이를 통해 Kafka는 메시지 처리 속도와 확장성을 향상시킬 수 있습니다.
파티션은 논리적인 메시지 저장 영역으로, 물리적인 브로커에 분산하여 저장됩니다. 각 파티션은 고유한 식별자와 시작 오프셋(starting offset), 끝 오프셋(ending offset)을 갖고 있습니다. 시작 오프셋은 파티션에서 메시지가 시작되는 위치를 나타내며, 끝 오프셋은 파티션에서 메시지가 끝나는 위치를 나타냅니다.
예를 들어, "order"라는 토픽이 있다고 가정해봅시다. 이 토픽은 3개의 파티션으로 구성되어 있을 수 있습니다. 첫 번째 파티션은 0번 파티션, 두 번째 파티션은 1번 파티션, 세 번째 파티션은 2번 파티션이 될 수 있습니다. 각 파티션은 각각 고유한 오프셋을 가지며, 순차적으로 메시지를 저장합니다.

예를 들어, "order" 토픽의 0번 파티션은 주문 번호가 1000부터 시작되는 메시지를 저장할 수 있고, 1번 파티션은 주문 번호가 2000부터 시작되는 메시지를 저장할 수 있습니다. 따라서, "order" 토픽의 메시지 중에서 주문 번호가 1500인 메시지는 0번 파티션에 저장될 수 없으며, 1번 파티션에 저장될 가능성이 높습니다.
이처럼 파티션을 이용하여 Kafka는 대용량 데이터 처리를 더욱 효율적으로 처리할 수 있습니다. 파티션을 이용하면 브로커를 수평적으로 확장하고, 분산된 데이터 처리를 구현할 수 있습니다.
Kafka에서 브로커란?
Kafka의 브로커는 Kafka 클러스터 내에서 메시지를 수신하고 발신하는 역할을 합니다. 브로커는 Kafka 클러스터를 구성하는 서버 중 하나이며, 각각의 브로커는 고유한 ID를 가지고 있습니다.
예를 들어, 3개의 브로커를 가진 Kafka 클러스터가 있다고 가정해보겠습니다. 이 경우, 각 브로커는 1부터 3까지의 고유한 ID를 가지고 있습니다. 이때 각 브로커는 브로커 ID와 함께 설정 파일을 사용하여 클러스터에 참여합니다.
Kafka 클러스터 내에서 브로커는 토픽을 관리하며, 각 토픽은 하나 이상의 파티션으로 구성됩니다. 파티션은 여러 브로커에 분산되어 저장되며, 각 브로커는 자신이 저장하는 파티션을 관리합니다. 또한, 브로커는 클러스터 내에서 메시지를 수신하고 발신하는 역할을 담당합니다.
예를 들어, "order"라는 토픽이 있다면, 이 토픽은 각 브로커에서 관리됩니다. "order" 토픽은 3개의 파티션으로 구성되어 있을 수 있으며, 각 파티션은 브로커에 분산되어 저장됩니다. 따라서, "order" 토픽의 메시지 중에서 0번 파티션에 저장된 메시지는 1번 브로커에서, 1번 파티션에 저장된 메시지는 2번 브로커에서, 2번 파티션에 저장된 메시지는 3번 브로커에서 관리됩니다.
이처럼 Kafka에서 브로커는 클러스터 내에서 중요한 역할을 수행하며, 대규모 데이터 처리를 위한 분산 시스템을 구성하는 데 필수적입니다.
아래는 추가로 참조해야 할 다른 블로그의 포스팅이다.